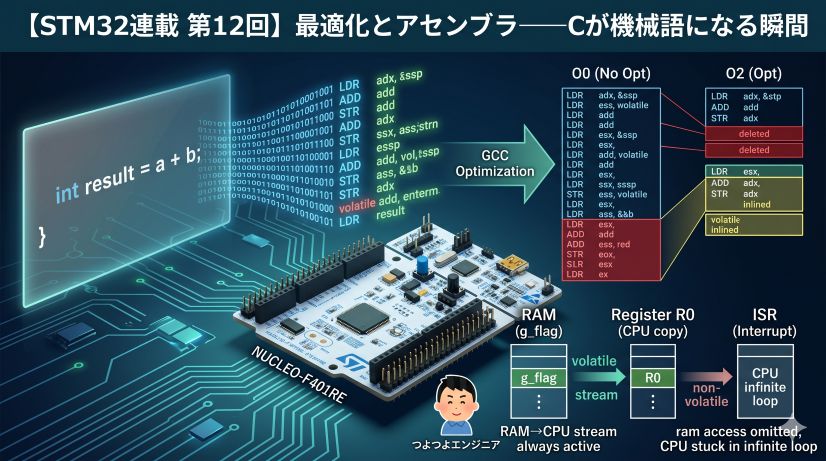
前回の第7回で、DWT CYCCNTを使って「実行時間を計測する」武器を手に入れました。計測はできました。しかし、まだCPUは受け身です。
「1msごとにセンサーを読みたい」 ——これをポーリングで実現しようとすると、HAL_GetTick() を監視し続けるループが必要です。その間、CPUは他の仕事ができません。
割り込みは、CPUを受け身から能動的に変える技術です。
「何かが起きたとき、CPUを強制的に呼び出す」——この仕組みを理解することが、組み込みエンジニアとして本当に「時間を支配する」出発点です。
今回は 「割り込みとは何か」 を仕組みのレベルから理解し、TIM2タイマ割り込みで1ms周期のイベントを生成するまでを実装します。
📍 連載トップページ
✅ この記事でできるようになること
- ポーリングと割り込みの違いと、それぞれの使い分けを説明できる
- ベクタテーブルの構造と、割り込みが発生したときのCPUの動きを説明できる
- NVIC(優先度・有効化・クリア)の役割と設定方法を理解できる
- コンテキスト保存(何がスタックに積まれるか)を図で説明できる
- TIM2割り込みで1ms周期のイベントを生成し、LEDをトグルできる
- ISR内で共有変数を扱う際の注意点(volatileの必要性)を説明できる
目次
- ポーリングの限界
- 割り込みとは何か――大局観
- ベクタテーブルの仕組み
- NVIC――優先度と許可の管理者
- コンテキスト保存――CPUが自動でやること
- TIM2割り込みを実装する
- ISRで共有変数を扱う(volatileと次回への伏線)
- まとめ
⏳ ポーリングの限界(STM32での問題点)
「待つ」ことの代償
第7回で測定した HAL_Delay(1) は「1ms以上待つ」関数でした。その間、CPUは何をしているかというと——
/* HAL_Delay の内部実装(簡略) */
void HAL_Delay(uint32_t Delay)
{
uint32_t tickstart = HAL_GetTick();
while ((HAL_GetTick() - tickstart) < Delay)
{
/* ← CPUはここで何もせずループし続ける */
}
}
CPUはひたすらカウンタを確認するだけで、約84,000サイクルを待機処理に使っています。
これが ポーリング(polling)です。「一定の間隔で状態を確認し続ける」手法で、シンプルですが欠点があります:
| 問題 | 内容 |
|---|---|
| CPUを独占する | 待機中は他の処理が一切できない |
| 精度が低い | SysTick割り込みの周期(1ms)に依存するため、µs精度の周期制御ができない |
| タスクが増えると破綻する | 「1msでセンサー読み取り」+「10msでLED更新」+「100msで通信」を同時にこなそうとすると、ループ1周にかかる時間が伸びるにつれて、どれか1つの周期がずれ始める |
「1msごとにセンサーを読む」をポーリングで書くと
/* ❌ ポーリングで周期処理をする:CPUが全力でカウンタを監視 */
uint32_t last_tick = 0;
while (1)
{
if (HAL_GetTick() - last_tick >= 1) /* 1ms 経ったか? */
{
last_tick = HAL_GetTick();
read_sensor(); /* センサー読み取り */
}
/* ↑ このループ中、CPUはひたすら GetTick() を呼び続ける */
/* 他にやることがあっても、ここを通らないといけない */
}
別の処理(通信・表示・計算)を追加するたびに、「ループが1周する時間」が伸びます。1ms周期の精度は徐々に崩れていきます。
割り込みはこれを根本的に解決します。
⚡ 割り込みとは何か——大局観
「電話が来たら手を止めて出る」
割り込みを一言で言えば、「ハードウェアが"今すぐ処理してくれ"とCPUに通知する仕組み」 です。
通常実行中:
CPU: main()を実行中...
↓
タイマが1msカウント完了!
↓
CPU: main()を中断、スタックに状態保存
↓
CPU: TIM2_IRQHandler() を実行
↓
CPU: 処理完了、スタックから状態復元
↓
CPU: 中断した場所から main() を再開
比喩で言えば、「作業中に電話が来て、今やっていることをメモに書いてから出て、電話が終わったらメモを見て作業を再開する」 です。
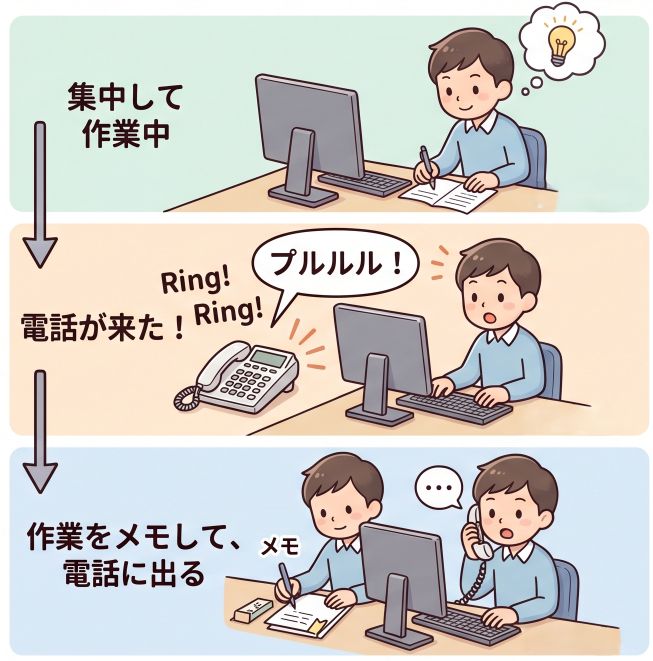
割り込みの比喩:電話が来たら作業をメモして出て、終わったら再開する
ポーリング vs 割り込み
| 方式 | 仕組み | 利点 | 欠点 |
|---|---|---|---|
| ポーリング | CPUが定期的に状態確認 | シンプル | CPUリソースを消費、精度が低い |
| 割り込み | ハードウェアがCPUに通知 | 効率的、高精度 | 設計が複雑、バグが潜みやすい |
「定期的に確認が必要で、間隔が短い(<1ms)」「他の処理と並行して実行したい」場合は割り込みが適切です。
「処理のタイミングが厳密でなくてよい」「シンプルさを優先したい」場合はポーリングでも問題ありません。割り込みは強力ですが、使わないで済むなら使わないという発想も大切です。
STM32の割り込み源
STM32F401RE で使える割り込み源は大きく2種類あります:
| 分類 | 例 | 用途 |
|---|---|---|
| ハードウェア割り込み(IRQ) | TIM, UART, SPI, GPIO(外部割り込み), DMA | 周辺機器からの通知 |
| 例外(Exception) | SysTick, HardFault, SVC, PendSV | システム管理・エラー処理 |
SysTick も「割り込み」の一種で、HALライブラリが1ms周期でカウンタを更新するために使っています。今回はタイマ TIM2 の割り込みを使います。
割り込みの概念は STM32 固有ではありません。他のメーカのマイコンでも名前が違うだけで同じ仕組みが存在します。
| マイコン | 割り込みコントローラ | タイマ割り込みの例 |
|---|---|---|
| STM32(ARM Cortex-M) | NVIC | TIM2_IRQHandler |
| Arduino / AVR(ATmega) | AVR割り込みベクタ | TIMER1_COMPA_vect |
| ESP32(Xtensa / RISC-V) | INTC | タイマ割り込みコールバック |
| Renesas RA(ARM Cortex-M) | NVIC(同じ ARM コア) | AGT/GPT 割り込みハンドラ |
| PIC | PIE/PIR レジスタ | TMR1 割り込みフラグ |
名前・レジスタ・API は違いますが、「ハードウェアがCPUに通知する」「ベクタテーブルでジャンプ先を決める」「ISR でフラグをクリアする」という本質はすべて共通です。STM32 でこの仕組みを腹落ちさせれば、他のマイコンへの移植もすぐに理解できます。
📋 ベクタテーブルの仕組み
「どの割り込みが来たら、どこを実行するか」の地図
割り込みが発生したとき、CPUはどこにジャンプすればよいかを知る必要があります。その答えが ベクタテーブル(Vector Table)です。
ベクタテーブルは Flashの先頭(アドレス 0x08000000) に置かれた、関数ポインタの配列です:
アドレス 内容 意味
0x08000000 スタックポインタの初期値 起動時にSPを設定する値
0x08000004 Reset_Handler のアドレス 電源ON時にジャンプする先
0x08000008 NMI_Handler のアドレス Non-Maskable Interrupt
0x0800000C HardFault_Handler のアドレス HardFaultが起きたとき
0x08000010 MemManage_Handler MPU違反
0x08000014 BusFault_Handler バスエラー
0x08000018 UsageFault_Handler 不正命令
...(4バイトずつ続く)
0x080000B8 TIM2_IRQHandler のアドレス TIM2のオーバーフロー/比較
...
割り込みが発生すると、CPUは次の手順を自動で実行します:
- 現在の実行状態をスタックに保存(コンテキスト保存)
- ベクタテーブルから、対応する割り込みの関数ポインタを読む
- そのアドレスにジャンプして、ISR(割り込みサービスルーチン)を実行
- ISR が返ったら、保存した状態を復元して中断箇所に戻る
/* スタートアップコード(startup_stm32f401retx.s)に定義されるベクタテーブルの一部 */
/* CubeIDE がプロジェクト生成時に自動で作成する */
g_pfnVectors:
.word _estack /* スタックポインタ初期値 */
.word Reset_Handler /* Reset */
.word NMI_Handler /* NMI */
.word HardFault_Handler /* HardFault */
/* ... 省略 ... */
.word TIM2_IRQHandler /* TIM2 */
CubeIDE が生成するスタートアップコードでは、TIM2_IRQHandler などのハンドラは __weak 属性付きの「空の無限ループ」として定義されています。__weak は「同名の関数が他に存在すれば、そちらを優先する」という GCC の機能です。
main.c や stm32f4xx_it.c に TIM2_IRQHandler を書くと、その実装が __weak 版を上書きします。CubeMX が生成する stm32f4xx_it.c にはこのしくみで HAL のハンドラが呼ばれます。「ベクタテーブルを書き換えているわけではなく、リンカがより強い定義を選ぶ」という仕組みです。
ベクタ番号とIRQ番号の関係
Cortex-M のベクタテーブルは、最初の16エントリが「コア例外(Reset/NMI/HardFaultなど)」で、それ以降がSTM32固有の周辺機器割り込み(IRQ)です。
ベクタ番号 IRQ番号(NVIC管理) 意味
0〜15 —(コア例外) Reset, NMI, HardFault, SysTick など
16〜 IRQ0 〜 周辺機器の割り込み(TIM2 = IRQ28)
TIM2 はベクタ番号44(= 16 + 28)に対応し、IRQ番号は28です。
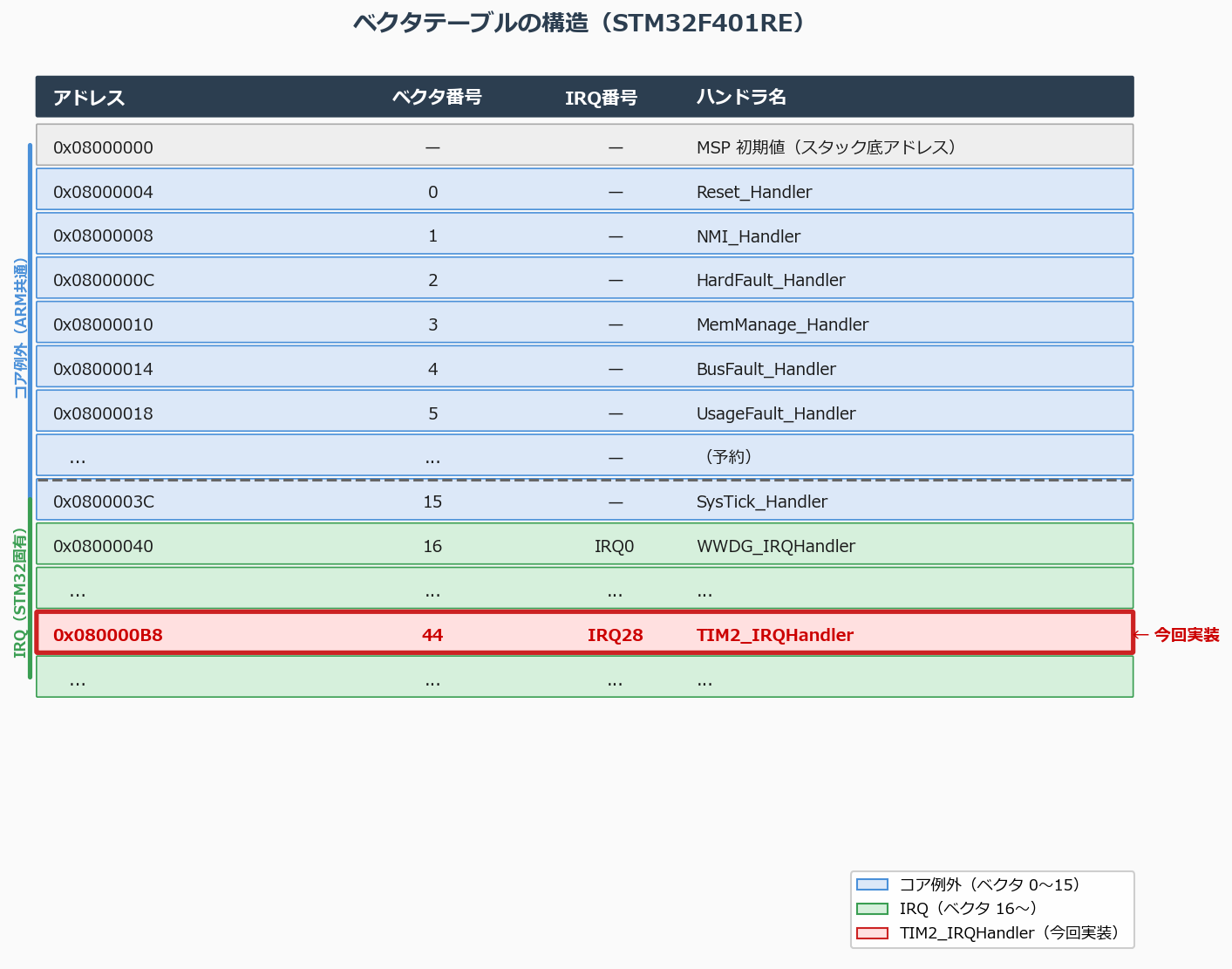
ベクタテーブルの構造。コア例外(0〜15)とIRQ(16〜)が連続して並ぶ。各エントリはISRのアドレス(4バイト)
🔧 NVIC——優先度と許可の管理者
NVIC とは
NVIC(Nested Vectored Interrupt Controller)は Cortex-M に内蔵されたハードウェアモジュールで、割り込みの優先度管理・有効化・無効化・保留クリア を担当します。
「どの割り込みを許可するか」「複数の割り込みが同時に来たらどちらを優先するか」——これをすべて NVIC が判断します。NVIC は 「どの割り込みをいつ実行するか」を決めるスケジューラ でもあります。
NVIC は ARM Cortex-M コア固有の名称です。他のマイコンでも「割り込みを管理するハードウェア」は必ず存在しますが、名前と操作方法が異なります。
| マイコン | 割り込み管理の仕組み | 優先度の設定方法 |
|---|---|---|
| STM32(Cortex-M) | NVIC(ARM 標準) | NVIC_SetPriority() |
| AVR(ATmega) | SREG の I ビット(グローバル許可のみ) | 優先度なし(ベクタ番号順) |
| ESP32(Xtensa) | INTC(Interrupt Controller) | esp_intr_alloc() でレベル指定 |
| Renesas RA(Cortex-M) | NVIC(同じ ARM コア) | STM32 と同じ API |
| PIC | PIE/PIR レジスタ + IPR レジスタ | HIGH/LOW の2段階 |
AVRのように「優先度の概念がない(ベクタ番号が小さい方が先)」マイコンもあれば、STM32のように細かく数値で設定できるものもあります。どちらにせよ「許可する・しない」「どちらを先に処理するか」という役割は共通です。
優先度の仕組み
STM32F401RE では4ビット(0〜15)で優先度を設定します。数字が小さいほど高優先度です。
優先度 0 ← 最強(他の割り込み処理中でも割り込める)
優先度 1
...
優先度 15 ← 最弱(すべての割り込みに横取りされる)
「0が最強、15が最弱」 と覚えてください。多くのCPUでは「数字が大きいほど優先度が高い」設計が多いため、STM32では逆になる点に注意が必要です。設定ミスの定番です。
STM32 の NVIC は「プリエンプション優先度」と「サブ優先度」を分けて設定できます。
プリエンプション優先度が異なる割り込みは、高優先度が低優先度の ISR に割り込めます(ネスト)。
サブ優先度は同一プリエンプション優先度の中での処理順序を決めます(割り込みはできない)。
HAL のデフォルトは4ビットすべてをプリエンプション優先度に使う設定(NVIC_PRIORITYGROUP_4)です。
複数の割り込みが重なったときの動作
「割り込みが同時に来たら、低優先度はキャンセルされるのか?」——これは非常に重要な疑問です。答えはキャンセルされません。
NVIC は割り込みの発生を Pending(保留)ビット として記録しています。割り込みを処理できない状況でも「来た」という事実はフラグに残り、条件が整い次第実行されます。
ケース1:低優先度ISR実行中に高優先度割り込みが来た(プリエンプション)
低優先度ISR(優先度2)を実行中
↓
高優先度割り込み(優先度0)が発生!
↓
低優先度ISRを中断 → スタックに状態を保存(コンテキスト保存)
↓
高優先度ISR(優先度0)を実行
↓
高優先度ISR が return
↓
低優先度ISRの続きを再開(スタックから状態を復元)
↓
低優先度ISR が return → main() に戻る
これを プリエンプション(preemption:割り込みの横取り)と呼びます。高優先度の割り込みは、低優先度のISRが終わるのを待たずに即座に割り込めます。ISRがネストする(多段に積み重なる)ため、スタックの消費量に注意が必要です。
ネスト時のスタックの積み上がり方:
← SP"] end subgraph s2["② 低優先度ISR 発生"] direction TB B2["8レジスタ保存(32バイト)
← SP"] A2["main のローカル変数"] B2 --- A2 end subgraph s3["③ 高優先度ISR が割り込む"] direction TB C3["8レジスタ保存(+32バイト)
← SP(現在位置)"] B3["低優先度ISR 保存分(32バイト)"] A3["main のローカル変数"] C3 --- B3 --- A3 end s1 -->|"低優先度割り込み発生"| s2 s2 -->|"高優先度割り込み発生"| s3
コンテキスト保存1回あたり 最低32バイト(8レジスタ × 4バイト)消費します。ISRが R4〜R11 も使う場合はさらに増えます。ネストが深くなるほどスタックは上に積み上がっていきます。
スタックがいっぱいになったら(スタックオーバーフロー):
STM32F401RE のスタックサイズはリンカスクリプトで決まっており、デフォルトは 0x200(512バイト) です。ネストが深すぎたり、ISR 内のローカル変数が大きすぎると、スタックが他のメモリ領域(グローバル変数やヒープ)を踏み越えます。
スタックオーバーフローが起きると:
→ グローバル変数が静かに破壊される(気づきにくい)
→ 最終的に HardFault または MPU Fault が発生して停止
→ デバッグが非常に困難(壊れた場所と原因が遠い)
プリエンプションを許可する優先度の組み合わせは最小限にするのが鉄則です。実用的なガイドライン:
- ネストの最大深さは2〜3段までを目安にする
- ISR 内のローカル変数は小さく保つ(大きなバッファをISR内で宣言しない)
- スタックサイズを増やす場合は
startup_stm32f401retx.sの_Min_Stack_Sizeを変更する - FreeRTOS などの RTOS を使う場合、各タスクにも独立したスタックが必要になる
「ISR が短い」はスタック消費の観点からも重要です。
ケース2:高優先度ISR実行中に低優先度割り込みが来た(保留)
高優先度ISR(優先度0)を実行中
↓
低優先度割り込み(優先度2)が発生!
↓
NVIC が Pending ビットをセット(「来た」と記録するだけ)
高優先度ISRはそのまま実行を続ける
↓
高優先度ISR が return
↓
NVIC が Pending ビットを検出 → 低優先度ISRを実行
↓
低優先度ISR が return → main() に戻る
低優先度の割り込みは キャンセルされず、保留状態のまま待ち続けます。高優先度ISRが終わった直後に自動で実行されます。
ケース3:同優先度の割り込みが重なった場合
同じ優先度の割り込みはプリエンプションできません。先に実行中のISRが終わるまで、後から来た割り込みは Pending 状態で待ちます。どちらが先に実行されるかはベクタ番号(小さいほど優先)で決まります。
| 状況 | 低優先度割り込みはどうなるか |
|---|---|
| 高優先度ISR実行中に低優先度割り込みが来た | 保留(Pending)→ 高優先度ISR終了後に実行 |
| 低優先度ISR実行中に高優先度割り込みが来た | 即座にプリエンプション(割り込みの横取り) |
| 同優先度ISR実行中に同優先度割り込みが来た | 保留(Pending)→ 実行中のISR終了後に実行 |
ISR 内でタイマやUARTの割り込みフラグをクリアし忘れると、ISR から return した瞬間に NVIC が「まだ Pending だ」と判断して即座に ISR を再呼び出しします。結果として ISR が永遠に繰り返され、main() に戻れなくなります。
「なぜか main() が動かない」というときは、ISR 内のフラグクリアを真っ先に疑ってください。
NVIC の操作(CMSIS API)
/* CMSIS が提供する NVIC 操作関数 */
/* ① 優先度を設定する */
NVIC_SetPriority(TIM2_IRQn, 1); /* TIM2 を優先度1に設定 */
/* ② 割り込みを有効化する */
NVIC_EnableIRQ(TIM2_IRQn); /* TIM2 IRQ を NVIC に許可 */
/* ③ 割り込みを無効化する */
NVIC_DisableIRQ(TIM2_IRQn);
/* ④ 保留中の割り込みをクリアする */
NVIC_ClearPendingIRQ(TIM2_IRQn);
CubeMX が生成するコードは HAL_NVIC_xxx 系を使います。
HAL_NVIC_SetPriority(TIM2_IRQn, 1, 0); /* プリエンプション=1, サブ=0 */
HAL_NVIC_EnableIRQ(TIM2_IRQn);
内部では CMSIS の NVIC_SetPriority() / NVIC_EnableIRQ() を呼んでいます。どちらを使っても同じ結果になります。
割り込みマスク(全体の有効/無効)
個別の NVIC 設定とは別に、CPU全体で割り込みを有効/無効にするグローバルマスクがあります:
__disable_irq(); /* PRIMASK = 1: すべての割り込みを禁止 */
/* 計測・クリティカルセクションなど */
__enable_irq(); /* PRIMASK = 0: 割り込みを再許可 */
第7回でも触れましたが、__disable_irq() 中は SysTick も止まるため HAL_Delay() が永久ループになります。クリティカルセクションは最小限(数µs以内)にとどめ、その区間内で HAL_Delay / HAL_GetTick に依存するコードを呼ばないようにしてください。
🗂️ コンテキスト保存——CPUが自動でやること
「作業を中断して戻ってくる」ために必要なもの
割り込みが発生すると、CPUは「今やっていた作業」を中断して ISR にジャンプします。ISR から戻った後、元の処理を正確に再開するためには、中断時点の CPU 状態を完全に保存する必要があります。
これが コンテキスト保存(Context Saving)です。
Cortex-M が自動で保存するレジスタ
割り込み発生時、Cortex-M は ハードウェアが自動で 次の8つのレジスタをスタックに積みます:
割り込み発生直後にスタックに積まれるもの(ハードウェアが自動):
スタック(RAM) レジスタ名 説明
+------------------+
| xPSR | プログラム状態レジスタ(フラグ類)
| PC(Return addr)| 中断箇所のアドレス(ISR返却後にここに戻る)
| LR | リンクレジスタ(呼び出し元アドレス)
| R12 | 汎用レジスタ
| R3 | 汎用レジスタ
| R2 | 汎用レジスタ
| R1 | 汎用レジスタ
| R0 | 汎用レジスタ ← SP はここを指す
+------------------+
(古い内容)
ISR から return すると、CPU はこれらを自動で復元し、プログラムカウンタ(PC)が示すアドレスから処理を再開します。
レジスタには「誰が守るか」のルールがあります。
- R0〜R3、R12 ── 「呼び出す側(main)が壊されても構わない」レジスタ。割り込み発生時にハードウェアが自動保存します。
- R4〜R11 ── 「使うなら自分(ISR)で守れ」レジスタ。ISR が実際に使う場合だけ、コンパイラが ISR の先頭(プロローグ)でスタックに保存し、終了時(エピローグ)に復元するコードを自動生成します。
つまり 「使わないレジスタは保存しなくていい」 という仕組みで、不要なスタック操作を省いています。ハードウェア保存の8レジスタと合わせて、割り込み前の状態が完全に復元されます。
コンテキスト保存のコスト
このスタック操作は何サイクルかかるのでしょうか?第7回で学んだ DWT CYCCNT で測定できます。
STM32F401RE(84MHz)での割り込みエントリのオーバーヘッドは、通常 12〜数十サイクル(約0.14〜数µs)です。この数字を頭に入れておくと、後で「ISR の実行時間」を考える際に役立ちます。
割り込みエントリ:
① NVIC が割り込みを検出 数サイクル
② ハードウェアがレジスタ8個を保存 約8〜12サイクル
③ ベクタテーブルを読む 1〜数サイクル
④ ISR にジャンプ 1サイクル
合計:最短でも 12〜16 サイクル程度
※ Flash wait state・キャッシュ状態・バス競合により数十サイクルになる場合もある
コンテキスト保存のオーバーヘッドがあるため、ISR の中身が短すぎると「オーバーヘッドの方が重い」という本末転倒になります。かといって長すぎると次の割り込みに間に合わなくなります。ISR のゴールデンルールは 「フラグをセットして main ループに仕事を渡す」 ——重い処理は ISR に書かず、main 側でこなすことです。詳細は第9回のアンチパターン集で掘り下げます。
Tail-Chaining と Late Arrival(Cortex-M の高速化機構)
Cortex-M には割り込み処理を高速化する2つのハードウェア最適化があります。知識として頭に入れておくと、実測値を見たときに腑に落ちます。
Tail-Chaining(テールチェーン)
ISR が終わった直後に別の割り込みが Pending 状態になっている場合、一度スタックを復元してから再び保存するという無駄を省き、スタック操作をスキップして次の ISR に直接ジャンプします。
通常(Tail-Chaining なし):
ISR-A 終了 → スタック復元(8レジスタ)→ ISR-B 開始 → スタック保存(8レジスタ)
Tail-Chaining あり:
ISR-A 終了 → ISR-B に直接ジャンプ(スタック操作なし)
連続する割り込みの処理が最短 6 サイクルで切り替わります。1ms 周期の TIM2 と UART 受信が連続するような場面で効いてきます。
Late Arrival(遅着割り込み)
コンテキスト保存の最中(まだ ISR に入っていない間)により高優先度の割り込みが到着した場合、ジャンプ先を高優先度の ISR に差し替えます。保存し直しのコストが発生しないため、高優先度の ISR が最速で起動できます。
これらは CPU が自動で行うため、ユーザーが意識する必要はありません。ただし「複数の割り込みが詰まったときに想定より速く処理が回る」場合はこの機構が働いています。
⏰ TIM2割り込みを実装する
全体像:TIM2で1ms周期割り込みを生成する
実装の流れは次の通りです:
① TIM2 の設定(プリスケーラ・カウンタ上限)
② TIM2 の割り込み(UEV: Update Event)を有効化
③ NVIC に TIM2_IRQn を登録・優先度設定
④ TIM2 スタート
⑤ TIM2_IRQHandler() で処理を書く
⑥ 割り込みフラグをクリア(重要!)
TIM2の動作原理
TIM2 は 16/32bitのアップカウンタです。クロックに同期して1ずつカウントアップし、設定した上限値(ARR: Auto-Reload Register)に達すると UEV(Update Event) が発生し、カウンタが0にリセットされます。
TIM2 カウンタの動き:
0 → 1 → 2 → ... → ARR → (UEV発生、割り込み!) → 0 → 1 → ...
↑
ここで ISR が走る
周期の計算式:
T_{period} = \frac{(\text{PSC} + 1) \times (\text{ARR} + 1)}{f_{TIM}}- PSC:プリスケーラ値(TIM2クロックを何分の1にするか)
- ARR:オートリロード値(いくつまでカウントするか)
- f_TIM:TIM2 に供給されるクロック周波数
第7回のクロックツリー図を思い出してください。TIM2 は APB1 バスに接続されており、F401RE のデフォルト設定では APB1 クロックは 42MHz です。ただし、APB1 プリスケーラが 1 でない場合、タイマへの供給クロックは APB1 クロックの 2倍(= 84MHz)になります。これは Cortex-M4 コアの仕様ではなく STM32 のタイマ固有の仕様です。他のARMマイコンでは動作が異なる場合があるため、移植時はリファレンスマニュアルを確認してください。
F401RE デフォルト設定(CubeMX の Clock Configuration タブで確認):
- SYSCLK: 84 MHz
- APB1 プリスケーラ: /2 → APB1 clock: 42 MHz
- TIM2 clock: 42 × 2 = 84 MHz
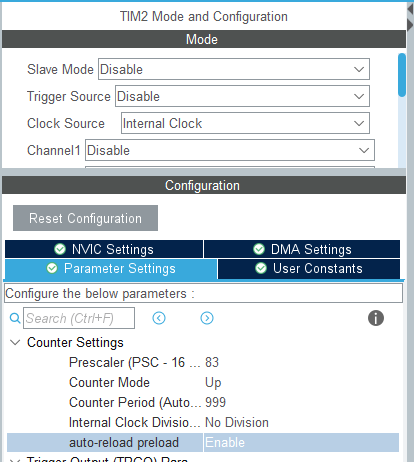
CubeMX の Clock Configuration タブ。APB1 Timer clocks が 84MHz になっていることを確認する
1ms 周期のパラメータ計算
タイマの周期は次の式で決まります:
T_{period} = \frac{(\text{PSC}+1) \times (\text{ARR}+1)}{f_{TIM}}CubeMX の Parameter Settings に入力した値を当てはめると:
| CubeMX の項目 | 設定値 | 意味 |
|---|---|---|
| Prescaler (PSC) | 83 | 84分周 → TIM2 clock を 84MHz ÷ 84 = 1MHz に落とす |
| Counter Period (ARR) | 999 | 1MHz で 1000 カウント → 1ms で UIF フラグが立つ |
ぴったり 1ms です。「PSC+1」「ARR+1」と +1 がつくのは、レジスタ値が 0 スタートのカウンタだからです(PSC=0 なら1分周、ARR=0 なら1カウントで溢れる)。
実装コード(レジスタ直接操作版)
/* main.c の USER CODE BEGIN PD に書く */
/* DWT(前回の計測用)*/
#define DWT_INIT() do { \
CoreDebug->DEMCR |= CoreDebug_DEMCR_TRCENA_Msk; \
DWT->CYCCNT = 0; \
DWT->CTRL |= DWT_CTRL_CYCCNTENA_Msk; \
} while(0)
#define DWT_START() (DWT->CYCCNT)
#define DWT_CYCLES(start) (DWT->CYCCNT - (start))
/* main.c の USER CODE BEGIN 0 に書く */
/* ISR から main に渡すフラグ(volatileが必須) */
volatile uint32_t g_tim2_tick = 0; /* 1msごとにインクリメント */
volatile uint32_t g_isr_cycle_count = 0; /* ISR の実行サイクル数(計測用)*/
/* TIM2 割り込みハンドラ */
void TIM2_IRQHandler(void)
{
uint32_t isr_start = DWT_START();
/* ① 割り込みフラグをクリア(必須! クリアしないと無限に割り込み続ける)*/
TIM2->SR &= ~TIM_SR_UIF;
/* ② フラグをインクリメント(処理本体は main でやる) */
g_tim2_tick++;
/* ③ ISR の実行時間を計測(デバッグ用) */
g_isr_cycle_count = DWT_CYCLES(isr_start);
}
/* main.c の USER CODE BEGIN 2 に書く */
/* DWT を初期化(計測用)*/
DWT_INIT();
/* ─── TIM2 初期化(レジスタ直接操作)───────────────────── */
/* ① RCC で TIM2 にクロックを供給する */
RCC->APB1ENR |= RCC_APB1ENR_TIM2EN;
/* ② TIM2 をリセット状態にする(念のため) */
TIM2->CR1 = 0;
/* ③ プリスケーラ設定:84分周 → TIM2 clock = 1 MHz */
TIM2->PSC = 84 - 1; /* PSC = 83 */
/* ④ オートリロード値設定:1000カウント → 1ms 周期 */
TIM2->ARR = 1000 - 1; /* ARR = 999 */
/* ⑤ UEV(Update Event)割り込みを有効化 */
TIM2->DIER |= TIM_DIER_UIE;
/* ─── NVIC 設定 ─────────────────────────────────────── */
/* ⑥ TIM2 IRQ の優先度設定(0〜15、小さいほど高優先度)*/
NVIC_SetPriority(TIM2_IRQn, 1);
/* ⑦ TIM2 IRQ を NVIC に有効化 */
NVIC_EnableIRQ(TIM2_IRQn);
/* ─── TIM2 スタート ─────────────────────────────────── */
/* ⑧ CEN ビットを立てて TIM2 カウント開始 */
TIM2->CR1 |= TIM_CR1_CEN;
/* main.c の USER CODE BEGIN WHILE に書く(while(1)ループ)*/
uint32_t last_tick = 0;
while (1)
{
/* g_tim2_tick が増えるまで待つ(メインループ側で処理)*/
if (g_tim2_tick != last_tick)
{
last_tick = g_tim2_tick;
/* 1ms ごとにここが実行される */
HAL_GPIO_TogglePin(GPIOA, GPIO_PIN_5); /* LD2(PA5)をトグル */
}
}
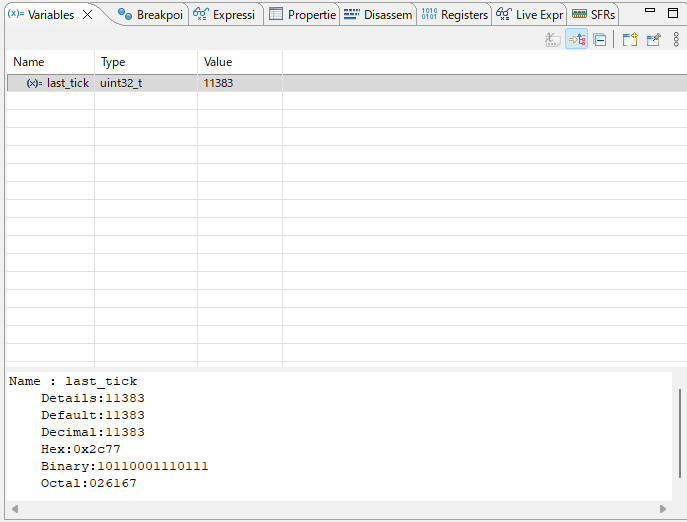
デバッガで g_tim2_tick の増加を確認。1msごとにインクリメントされ、1000回で1秒経過することが分かる
HAL版との比較
CubeMXを使うと、同じことが次のように書けます:
/* HAL 版(CubeMX が生成するコードを使う場合)*/
/* main.c の MX_TIM2_Init() に生成されるコード(自動)*/
htim2.Instance = TIM2;
htim2.Init.Prescaler = 84 - 1;
htim2.Init.CounterMode = TIM_COUNTERMODE_UP;
htim2.Init.Period = 1000 - 1;
htim2.Init.ClockDivision = TIM_CLOCKDIVISION_DIV1;
HAL_TIM_Base_Init(&htim2);
/* main.c の USER CODE BEGIN 2 */
HAL_TIM_Base_Start_IT(&htim2); /* 割り込みありでTIM2スタート */
/* stm32f4xx_it.c の TIM2_IRQHandler(自動生成)*/
void TIM2_IRQHandler(void)
{
HAL_TIM_IRQHandler(&htim2); /* フラグクリアも内部でやってくれる */
}
/* main.c の Callback(自分で書く)*/
void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef *htim)
{
if (htim->Instance == TIM2)
{
g_tim2_tick++; /* 1ms ごとに呼ばれる */
}
}
HAL版では HAL_TIM_Base_Start_IT() が NVIC の設定も含めて行います。ただし NVIC の優先度は、CubeMX の「NVIC Settings」タブで事前に設定しておく必要があります。レジスタ直接操作版を理解した上でHAL版を使うと、「HALが内部で何をしているか」が分かり、問題発生時のデバッグが格段に楽になります。
動作確認
デバッガで g_tim2_tick の値を確認しながら1秒待つと、約1000 になっているはずです。ほぼ正確な1ms精度が得られています。
また g_isr_cycle_count を確認すると、ISR本体(フラグクリア + カウンタインクリメント)のサイクル数が見えます。計測結果の例:
g_isr_cycle_count ≈ 8〜12 サイクル(約0.1〜0.15 µs)
割り込みエントリのオーバーヘッドも合わせると:
トータル割り込み処理 ≈ 20〜30 サイクル(約0.25〜0.36 µs)
1ms = 84,000 サイクルのうち、割り込みのコストは 0.03% 程度
1ms周期(84,000サイクル)に対しては、30サイクル未満の割り込みオーバーヘッドは無視できる大きさです。 ただし高周波割り込み(数十µs以下の周期)や RTOS 環境ではオーバーヘッドが無視できなくなる場合があります。
TIM2->SR &= ~TIM_SR_UIF; を書き忘れると、ISRから戻った瞬間にまた割り込みが発生し、CPUが ISR から抜け出せない無限ループになります。割り込みハンドラを書いたら、まず「フラグクリアはあるか?」を確認してください。
HAL版では HAL_TIM_IRQHandler() 内部でフラグクリアが行われています。
コード例ではフラグクリアを処理の冒頭に置いています。「終わってからクリアすればよいのでは?」と思うかもしれませんが、末尾に書くのは危険です。
STM32ではフラグクリア命令を書いてからハードウェアに反映されるまで、バスアクセスの都合で数サイクルの遅延が生じることがあります。ISRの最後にクリアすると、クリアが確定する前にISRが return してしまい、NVIC が「まだフラグが立っている」と見なして即座に再エントリするケースがあります。特に高速クロック・低レイテンシ環境(STM32F4 の 84MHz など)で発生しやすい問題です。
「入り口でまずクリアする」 ことで、この二重エントリのリスクをゼロにできます。また、クリアのし忘れに気づきやすくなるという副次効果もあります。
⚠️ ISRで共有変数を扱う(volatileと次回への伏線)
なぜ volatile が必要か
g_tim2_tick に volatile を付けていることに気づきましたか?
volatile uint32_t g_tim2_tick = 0; /* volatile が必須 */
第6回で学んだ最適化バグを思い出してください。volatile なしで書いた場合、-O2 ビルドでは次のことが起きます:
main() の while(1) ループ内:
-O0 の場合:
毎回 RAM から g_tim2_tick を読み直す → 割り込みで変化が見える ✅
-O2 の場合:
「このループの中で g_tim2_tick を変えるコードがない」とコンパイラが判断
→ 最初に一度だけ RAM から読んで、以降はレジスタにキャッシュしたままにする
→ ISR が RAM の値を書き換えても、main は見えない → 無限ループ ❌
volatile は「このメモリはコンパイラが知らないタイミングで変わる」という宣言です。ISR・DMA・ハードウェアが書き換える変数には必ず付けます。
アトミック性の問題(次回の予告)
しかし volatile を付けるだけでは不十分な場合があります:
/* ❌ 32bit変数の読み書きがアトミックでない可能性(マルチバイト更新)*/
volatile uint32_t g_sensor_value = 0;
/* ISR 内 */
void TIM2_IRQHandler(void) {
TIM2->SR &= ~TIM_SR_UIF;
g_sensor_value = read_sensor(); /* 32bit の書き込み */
}
/* main 内 */
uint32_t val = g_sensor_value; /* 32bit の読み込み */
/* ← 読み込みと ISR の書き込みが重なったら? */
Cortex-M4 は 32bit CPU なので、アラインされた32bit変数(uint32_t)の読み書きは1命令(LDR/STR)で完結します。「1命令で完結する = 途中で割り込まれない」、これがアトミックの物理的な意味です。第7回で学んだ「1サイクルの重さ」と同じ感覚で、「32bit CPUは32bitを一度に運べる」と覚えてください。「アラインされた」とは、アドレスが4の倍数に配置されていることで、通常のグローバル変数・ローカル変数は自動的にアラインされます。
ただし、64bit変数・構造体・複数変数の組み合わせ更新 では1命令では完結せず、アトミックになりません。
/* ❌ 複数変数を「まとめて」更新する場合は途中で割り込みが入り得る */
volatile uint32_t g_timestamp = 0;
volatile uint32_t g_value = 0;
/* ISR 内 */
g_timestamp = current_time; /* ← ここで割り込みが入ったら? */
g_value = new_value; /* main が g_timestamp だけ新しい値を読む */
これを防ぐには クリティカルセクション(割り込み禁止区間)が必要です。詳細は次回の第9回「割り込みアンチパターン集」で徹底的に扱います。
ISR と main が共有する変数に volatile を付けることは必須ですが、それだけでは「途中で割り込まれない保証(アトミック性)」は得られません。1変数の uint32_t 読み書きは Cortex-M4 ではアトミックですが、複数変数を一貫した状態で扱いたい場合はクリティカルセクションが必要です。
まとめ
今回学んだこと:
- ポーリングの限界 → CPUを独占し、精度が低く、スケールしない
- 割り込みの本質 → ハードウェアがCPUに「今すぐ処理してくれ」と通知する仕組み
- ベクタテーブル → Flashの先頭に並ぶISRアドレスの配列。割り込み発生時にCPUが参照する
- NVIC → 優先度・有効化・クリアを管理するハードウェアコントローラ
- コンテキスト保存 → 割り込み時にCPUが自動でレジスタ8個をスタックに保存・復元する
- TIM2割り込み実装 → PSC/ARR でタイマ周期を設定し、UIFフラグクリアを忘れずに
- volatile の必要性 → ISR と共有する変数には必ず付ける
割り込みが「怖い」のは、「コードのどこでISRが割り込んでくるか分からない」からです。しかし設計原則を守れば制御できます。
- 短く――ISRの実行時間は次の割り込みまでに確実に終わる長さに収める
- 副作用を最小に――グローバル変数への書き込みを最小限にし、フラグ通知に徹する
- 共有変数を保護する――ISR と main が触る変数には
volatile、複数変数をまとめて更新するときはクリティカルセクションを使う
次回はこの原則を破ったらどうなるかを、わざと壊して体験します。
割り込みは「便利な関数呼び出し」ではなく、「非同期に割り込んでくる別世界の処理」 です。この感覚を持てるかどうかが、組み込み設計の分水嶺になります。
次回は 「割り込み設計アンチパターン集」 です。「ISR で printf する」「重い処理をISRに書く」「volatile を付け忘れる」——組み込み開発でよく踏む地雷を、わざとやって壊しながら学びます。
次回予告
🔥 第9回:割り込み設計アンチパターン集【超重要】
ISRで重い処理をする・printfする(致命的)・shared変数を雑に触る・volatile乱用/不足……よく踏む地雷を「わざと」やって壊す、つよつよの分水嶺となる第9回。
📖 第9回を読むよくある質問(FAQ)
Q. 割り込みとポーリング、どちらを使うべきですか?
タイミング精度が必要(µs単位)・他の処理と並行して動かしたい場合は割り込みが適切です。精度が不要でシンプルに書きたいならポーリングで問題ありません。「使わないで済むなら使わない」が基本方針です。
Q. ISRの中でprintf(UART送信)してもいいですか?
原則 NG です。UART送信はブロッキング処理になりやすく、ISRの実行時間が長くなり他の割り込みを阻害します。また、HAL の UART 関数は内部で待ち処理を行うため、ISR 内で呼ぶとデッドロックの原因にもなります。デバッグ出力は LED や DWT による計測で代替してください。第9回で詳しく扱います。
Q. 割り込みが止まらない(main() に戻れない)原因は何ですか?
ISR 内でフラグをクリアし忘れているケースがほとんどです。TIM2->SR &= ~TIM_SR_UIF; のようなクリア処理を ISR の冒頭に書いているか確認してください。
Q. 優先度はいくつに設定すればいいですか?
迷ったら 1(高め)から始めてください。SysTick(HAL が使用)はデフォルト優先度0のため、TIM2 を 0 に設定すると SysTick と競合する可能性があります。1 以上に設定しておくのが安全です。
Q. HAL版とレジスタ直接操作版、どちらを使うべきですか?
実務では HAL 版が安全で保守しやすいです。ただし「HAL が内部で何をしているか」を理解するためにレジスタ版を一度手で書いておくと、問題発生時のデバッグ力が大きく変わります。